Datakwaliteit maakt het verschil bij migraties
Datamigratie kan niet zonder beheersing van de datakwaliteit, ook al zouden sommige projectleiders het datakwaliteitsaspect het liefst buiten hun project willen duwen, onder het motto: 'garbage in - garbage out' of 'datamigratie as-is'. Maar daar kom je niet mee weg.
Datamigratie kan niet zonder beheersing van de datakwaliteit, ook al zouden sommige projectleiders het datakwaliteitsaspect het liefst buiten hun project willen duwen, onder het motto: 'garbage in - garbage out' of 'datamigratie as-is'. Maar daar kom je m.i. niet mee weg. Voor de business is het essentieel dat de brondata gemigreerd kunnen worden en dat deze voldoen aan de gestelde kwaliteitseisen, zodat de bedrijfsprocessen correct kunnen worden uitgevoerd. Dat betreft niet alleen de bedrijfsprocessen die met het doelsysteem worden ondersteund. Het doelsysteem zal de gegevens mogelijk ook doorgeven aan andere systemen en ook daar gelden eisen voor de datakwaliteit.
Hoe doe je dat?
Ten eerste moet duidelijk zijn welke kwaliteitseisen er gelden en hoe hard deze zijn. Ook moet je een mechanisme hebben om data die hier niet aan voldoen te traceren en om hierover te rapporteren. Op basis daarvan kan besluitvorming plaats vinden over wat er met de slechte data moet gebeuren. De organisatie van die besluitvorming vraagt om een vorm van governance - een procedure of werkwijze met duidelijke verantwoordelijkheden en mandaten. Er zijn 4 mogelijke uitkomsten van deze besluitvorming. Dat maakt het lekker overzichtelijk. Iedereen weet daarna waar die aan toe is. In de tussentijd kunnen we de data waarbij geen fouten zijn waargenomen doorsturen naar het doelsysteem voor een proefmigratie. Ook al is de datakwaliteit nog niet op het gewenste niveau, hij is wel under control.
Inventariseren kwaliteitseisen
Begin met de inventarisatie van de kwaliteitseisen die voortkomen uit het laadproces van de doeldata. De doeldata worden via een speciale procedure of interface in het doelsysteem geladen. Als het goed is heb je een beschrijving gemaakt van de onderliggende datastructuur. Dat is immers waar je met de conversie (ook wel transformatie) van de gegevens naar toe werkt. Het laadproces zal voorafgaand aan of tijdens het laden bepaalde checks uitvoeren. Deze checks wil je goed in beeld hebben. Zij beschrijven de minimale datakwaliteit waaraan de data moeten voldoen. Aanvullend hierop zullen er vereisten zijn die voorvloeien uit de functionaliteit van het doelsysteem. Misschien wordt er bij het laden van de gegevens nog niet gecheckt of er voor iedere medewerker een bankrekeningnummer bekend is. Maar voor het kunnen betalen van de salarissen is dat echter wel noodzakelijk. Ook dergelijke eisen moeten dus toegevoegd worden aan je inventarisatie. Nog een stap verder is dat je ook voor de afnemers van de data uit het doelsysteem nagaat welke essentiële datakwaliteitseisen er gelden.
Voor de datamigratie is het essentieel dat je al deze kwaliteitseisen uitdrukt in termen van de doeldata, dus op basis van de onderliggende datastructuur van het laadproces. Hopelijk heb je de beschrijving van die doeldata opgenomen in een datadictionary of iets dergelijks. In andere woorden: de hebt de metadata van de doeldata gemodelleerd - waarbij je natuurlijk alle regels van datamodellering hebt toegepast. Veel van de geïnventariseerde kwaliteitseisen kun je dan aan die datadictionary toevoegen. Bijvoorbeeld of een veld verplicht is of de referentiële integriteit die moet gelden, maar ook wat de uniciteitsregels zijn, etc. Datakwaliteitseisen zijn in twee groepen in te delen. De eerste groep bestaat uit de eisen die je kunt uitdrukken in termen van het onderliggende metamodel - meestal het relationele model.
De andere groep bestaat uit alle overige kwaliteitseisen. Deze zullen moeten worden gespecificeerd middels een stukje (pseudo-)code, bijvoorbeeld SQL, toegelicht in gewone-mensen-taal.
Slechte data opsporen en rapporteren
Nu we weten aan welke eisen de doeldata moeten voldoen kunnen we iets maken dat opzoek gaat naar overtredingen. In ons datamigratieproces hebben we de brondata gekopieerd naar een afzonderlijke conversiedatabase en hebben we de conversie uitgevoerd wat leidde tot een set van tabellen die overeenkomen met de datastructuur van het laadproces.
Een mogelijkheid zou kunnen zijn dat we de kwaliteitseisen implementeren in de conversiedatabase. Dus dat we een uniciteitsregel implementeren als een Primary Key of een Unique Constraint, etc. Maar dat heeft niet mijn voorkeur. Sterker nog: ik doe dat nooit. Het is veel fijner als het conversieproces al zijn data kan wegschrijven in de doeltabellen en de datakwaliteitscontrole in een aparte slag er achteraan komt. Dit is voor de opbouw van datakwaliteitsrapportages namelijk veel handiger. Bij de check op de datakwaliteit schrijven we de id's van de foutieve records weg naar een aparte tabel in combinatie met een code die de foutsoort aangeeft. NB Tijdens de conversieslag heeft ieder record een id gekregen waarmee ook een relatie is gelegd met het bronrecord. De tabel met id's van foutieve records wordt vervolgens gebruikt voor de rapportages. Voor iedere foutsoort hebben we een query gedefinieerd voor de relevante gegevens in de rapportage. Dat zijn namelijk voor iedere foutsoort andere gegevens. Stel dat de schoenmaat van een medewerker een verplicht veld is en dat die bij 130 medewerkers ontbreekt en dat die alleen achterhaald kan worden door de medewerker op te bellen. Dan is het wel zo handig om in het rapport voor deze foutsituatie het telefoonnummer van de medewerker te vermelden. HR kan in dat geval gemakkelijk contact opnemen met de medewerker en de schoenmaat in het bronsysteem invullen.
Filtering van schone data
Nu we weten welke records fout zijn, weten we ook welke records goed zijn. Althans volgens de kwaliteitseisen zoals we die geïnventariseerd hebben. Al is het goed mogelijk - zeker bij de eerste paar proefmigraties - dat we er gaande weg achter komen dat de kwaliteitseisen nog moeten worden bijgesteld.
Als we in een proefmigratie gegevens willen laden in het doelsysteem, dan willen we daar zo schoon mogelijke data voor gebruiken. De gemigreerde data zal waarschijnlijk ook gebruikt worden om de functionaliteit van het nieuwe systeem te testen. Foutieve data zou tot vreemde resultaten kunnen leiden waardoor de test eigenlijk niet representatief is.
Voor het opleveren van schone data is het niet voldoende om alleen de foutieve records tegen te houden. Dat zou immers kunnen leiden tot een inconsistente dataset, met bijvoorbeeld 'wezen' of 'kinderloze ouders'. Stel dat er een probleem is op een medewerkerrecord maar niet op de onderliggende adresrecords van deze medewerker. Je wilt in dit voorbeeld niet dat de adresrecords naar het doelsysteem worden gestuurd. Op basis van de gedefinieerde relaties moeten deze adresrecords ook tegengehouden worden. Het functioneren van dit filter is afhankelijk van de relaties die voor de doeldata gedefinieerd zijn.
Besluitvorming
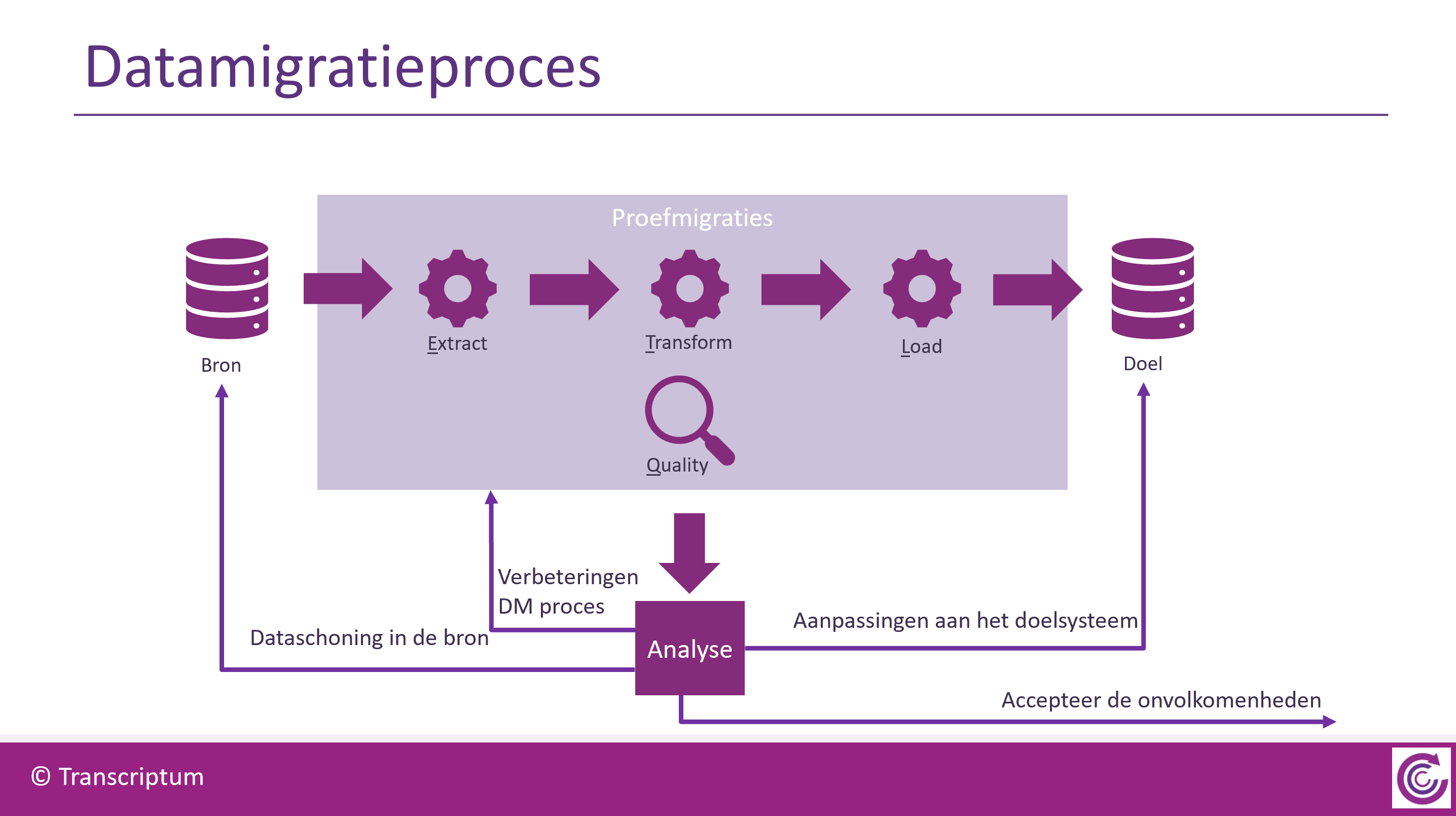
De rapportage over de gevonden datafouten is de input voor een besluitvormingsproces. Per foutsoort moet worden geanalyseerd wat er misgaat, wat de oorzaak is en welke consequenties het heeft. Dan kunnen één of meer mogelijke oplossingen worden voorgesteld. Er zijn slechts 4 soorten oplossingen:
- Dataschoning in de bron
- Aanpassen of aanvullen conversieregels
- Aanpassing aan het doelsysteem (bijvoorbeeld de uitbreiding van het waardenbereik van een veld)
- Accepteren dat de gegevens niet of niet optimaal gemigreerd worden. Eventueel kan na Go Live nog een verbeterslag plaatsvinden in het doelsysteem.
Deze laatste optie is een hele belangrijke. We kunnen misschien wel heel dicht in de buurt komen van een 100% migratie. Maar die laatste procenten kosten meestal wel de meeste tijd en dus het meeste geld. Misschien is het verstandiger om niet naar een 100% migratie te streven.
Doordat we de besluitvorming heel direct baseren op de rapportage van de datakwaliteit wordt het voor iedereen, met name ook voor de business-vertegenwoordigers, heel concreet. Met iedere beslissing worden de acceptatiecriteria weer wat scherper. Aan het begin van het datamigratieproject is het heel moeilijk om de acceptatiecriteria concreet te maken. Vaak zijn deze slechts gebaseerd op drijfzand van slecht gedefinieerde begrippen die voor meerdere uitleg vatbaar zijn. Het besluitvormingsproces dat we langs de hierboven geschetste lijnen neerzetten is een belangrijk instrument voor het verwachtingsmanagement en draagt in belangrijke mate bij tot de acceptatie van de datamigratie en de tevredenheid van eindgebruikers.
Niet alleen het eindresultaat van de datamigratie brengen we hiermee op orde. Ook de manier waarop dat gebeurt verloopt gestructureerd en voorspelbaar. Ook al blijft er nog veel te doen, het project is nu in control.