Gebruik van metadata Microsoft Dynamics CRM
Bij de implementatie van een Microsoft CRM systeem moeten vaak de gegevens uit andere systemen worden opgehaald en gemigreerd naar het nieuwe systeem. Zo’n migratie is uitdagende klus waarbij het datamodel van het bestaande systeem moet worden vertaald naar het datamodel van het nieuwe systeem.
Datamigratie als brug
Datamigratie is het slaan van een brug tussen twee vaak nog onbekende en zelfs bewegende
oevers. De documentatie van het bronsysteem is vaak niet meer actueel en gebruikers zijn in de loop der jaren vaak creatief met het systeem omgegaan, waardoor de wijze waarop de database in de praktijk gevuld is, afwijkt van de oorspronkelijke bedoelingen zoals die zijn weergegeven in de documentatie van het systeem. In de periode waarin de datamigratie wordt voorbereid, is het doelsysteem vaak nog in ontwikkeling – soms met maatwerk, soms alleen met het configureren van entiteiten en attributen. Daardoor is het lastig om goede en actuele informatie te krijgen over het doelsysteem.
Het vergaren van voldoende kennis over bron- en doelsysteem is een van de grootste uitdagingen bij een datamigratie. Uiteraard gaan we op zoek naar de mensen die over de meeste kennis beschikken. Voor het opbouwen van kennis over de brongegevens is data profiling een nuttig hulpmiddel. We onderzoeken de bronbestanden om inzicht te vergaren in de werkelijke vulling daarvan. Dit geeft ons allengs meer vaste grond onder de voeten op de oever van het bronsysteem.
Ook aan de andere oever zoeken we naar stevige ankerpunten. Een belangrijke vraag daarbij is: Wat zijn de data requirements van het doelsysteem? Oftewel: Hoe zien de gegevens eruit, die geladen moeten worden? Wat zijn de onderlinge relaties? Wat zijn de toegestane waarden voor de afzonderlijke gegevenselementen? En zo verder.
Metadata Microsoft CRM
Voor datamigraties naar Microsoft Dynamics CRM hebben we een tool ontwikkeld waarmee de relevante kennis (de meta-informatie) opgehaald wordt uit de systeem catalogus en geïntegreerd wordt met onze datamigratie-omgeving en tools.
De grote voordelen hiervan zijn:
- Altijd de actuele stand van zaken met betrekking tot de 'technische' data requirements.
- Automatisch inlezen van de metadata van het doelsysteem in de datamigratie-omgeving.
- Stabiele basis voor afstemming met betrokkenen.
- Mogelijkheid voor geautomatiseerde aansluitcontroles tussen datamigratie-omgeving en het doelsysteem.
Een bijkomend voordeel is dat deze informatie over de inrichting van het Microsoft Dynamics CRM systeem ook nuttig is voor anderen die betrokken zijn bij de implementatie, zoals testers en trainers.
Hoe werkt het?
Een Microsoft Dynamics CRM systeem configureer je op het niveau van entiteiten, zoals Account, Contract en Invoice. Out of the box komt Microsoft CRM met heel veel vooraf geconfigureerde entiteiten. Al deze entiteiten kunnen verder worden aangepast aan de behoeften van de organisatie en ook kunnen geheel eigen entiteiten gemaakt worden. Microsoft CRM vertaalt deze informatie voor SQL Server naar tabellen, kolommen, foreign keys, views en dergelijke.
Bij de datamigratie naar Microsoft CRM laden we de geconverteerde gegevens niet rechtstreeks in de tabellen van SQL Server. In plaats daarvan worden de gegevens geladen via de standaard interface (API) van Microsoft CRM. Daarom worden de gegevens vanuit de datamigratie-omgeving aangeboden in de structuur van de entiteiten en niet van de onderliggende tabellen. Daarvoor
hebben we de metagegevens op entiteitenniveau nodig. Deze worden binnen de SQL Sever database opgeslagen in aparte tabellen in het z.g. metadataschema.
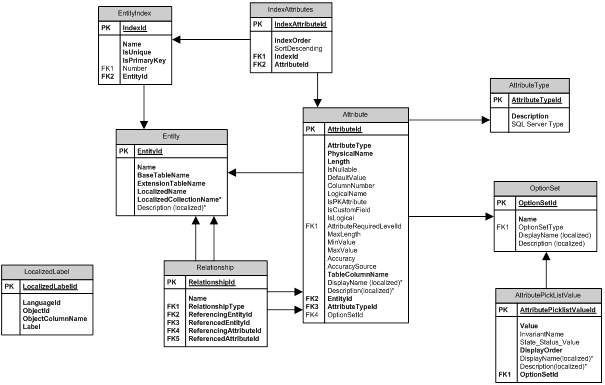
Hier vinden we bijna alle informatie die we nodig hebben: de entiteiten, velden, relaties, toegestane waarden, etc. Met een aantal SQL statements halen we die informatie op om in ons eigen tool te integreren.
Wat hier nog mist is de informatie over op welke schermen (Forms) de velden van een entiteit voorkomen. Deze informatie kunnen we wel ophalen uit de deployment file customizations.xml.
Ook deze informatie integreren we in onze datamigratie-omgeving.

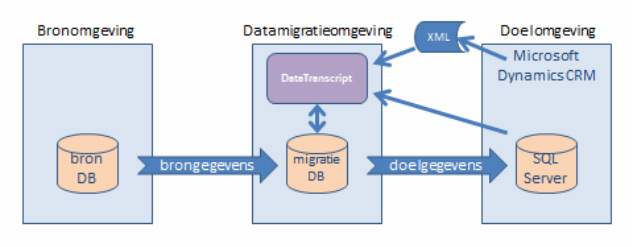
Overzicht
Onderstaande plaatje brengt in beeld hoe deze metadata uit Microsoft CRM geïntegreerd wordt binnen onze datamigratiestraat. We onderscheiden drie omgevingen: de bron- en doelomgeving met daartussen een afzonderlijke datamigratie-omgeving. Binnen de datamigratie-omgeving hebben we
een migratiedatabase waarin we kopie bewaren van de brongegevens en waar we deze converteren naar het formaat waarin ze aan de doelomgeving moeten worden aangeboden. Voor die conversie en de kwaliteitsbewaking gebruiken we onze migratietooling DataTranscript. Deze tooling wordt gevoed met de metadata van bron- en doelsysteem. Op basis daarvan worden mappings gemaakt en conversiescripts gegenereerd.